welcome
Portfolio
효과적인 바이럴 전략으로 브랜드 가치를 높이는 마케팅에 주력해 왔습니다.
최근에는 클라우드 기술과 코딩 역량을 바탕으로
마케팅과 기술 영업의 전문가로 성장하겠습니다.

김병현 (1995.01.23)
Mail : tw8542@naver.com
데이터를 활용해 산업의 가치를 창출하며 성장하고자 하는
김병현 입니다.
Education
- 2020: 북화 대학교 국제 중국어 교육학과 졸업
- 2013: 한국 외식 과학 고등학교 관광과 졸업
Career
- 2025.02 - 현재: KDSys㈜ (사원)
- 2024.08 - 2024.10: SK쉴더스 (실습생)
- 2021.08 - 2023.11: ㈜애드원마케팅 (사원)
Certificates
- 2025.01: 리눅스 마스터 2급
- 2024.12: 네트워크 관리사 2급
- 2024.06: NCA
- 2021.08: GTQ
- 2021.07: 컴퓨터그래픽스운용기능사
- 2021.05: GTQi
Skills

Photoshop

Illustrator

Premiere Pro

Linux

Python
Military
- 2016.09 - 2018.06: 병장 복무 완료

1. 애드원 마케팅 (21.08 ~ 23.11)
1-1. 네이버 플랫폼의 기반으로한 검색광고
진행 배경
- 약 2년간 마케팅 회사에서 근무하며,
광고 실행사의 핵심 역할을 맡아 광고 진행과 매출 관리를 책임졌습니다.
대행사로부터 맡은 광고를 정확하고 효율적으로 실행하여,
2명에서 월 3300만 원의 매출을 달성했고,
이후 혼자서도 월 2200만 원의 매출을 관리하며 성과를 이어갔습니다.
담당업무 및 진행사항
광고주 연락
→
키워드 선별
→
협의
→
광고 진행
관리 내역
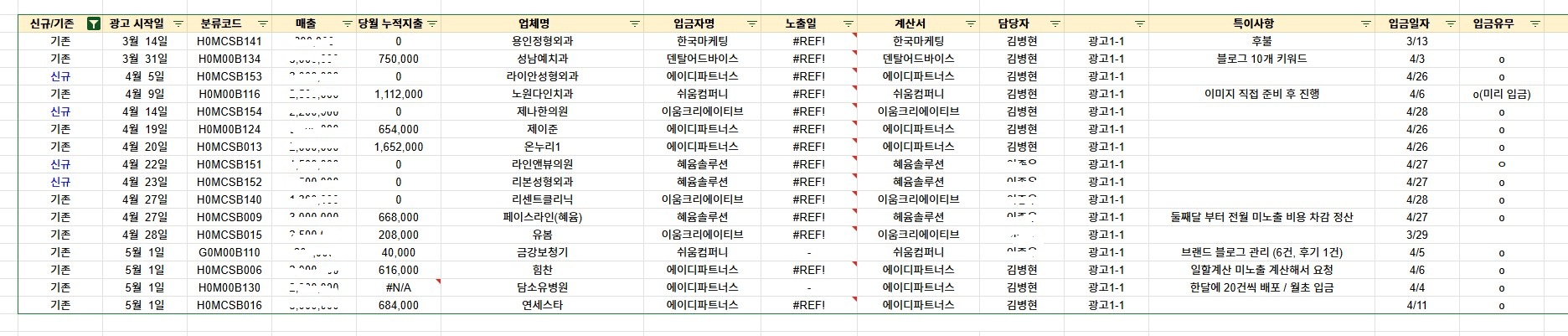
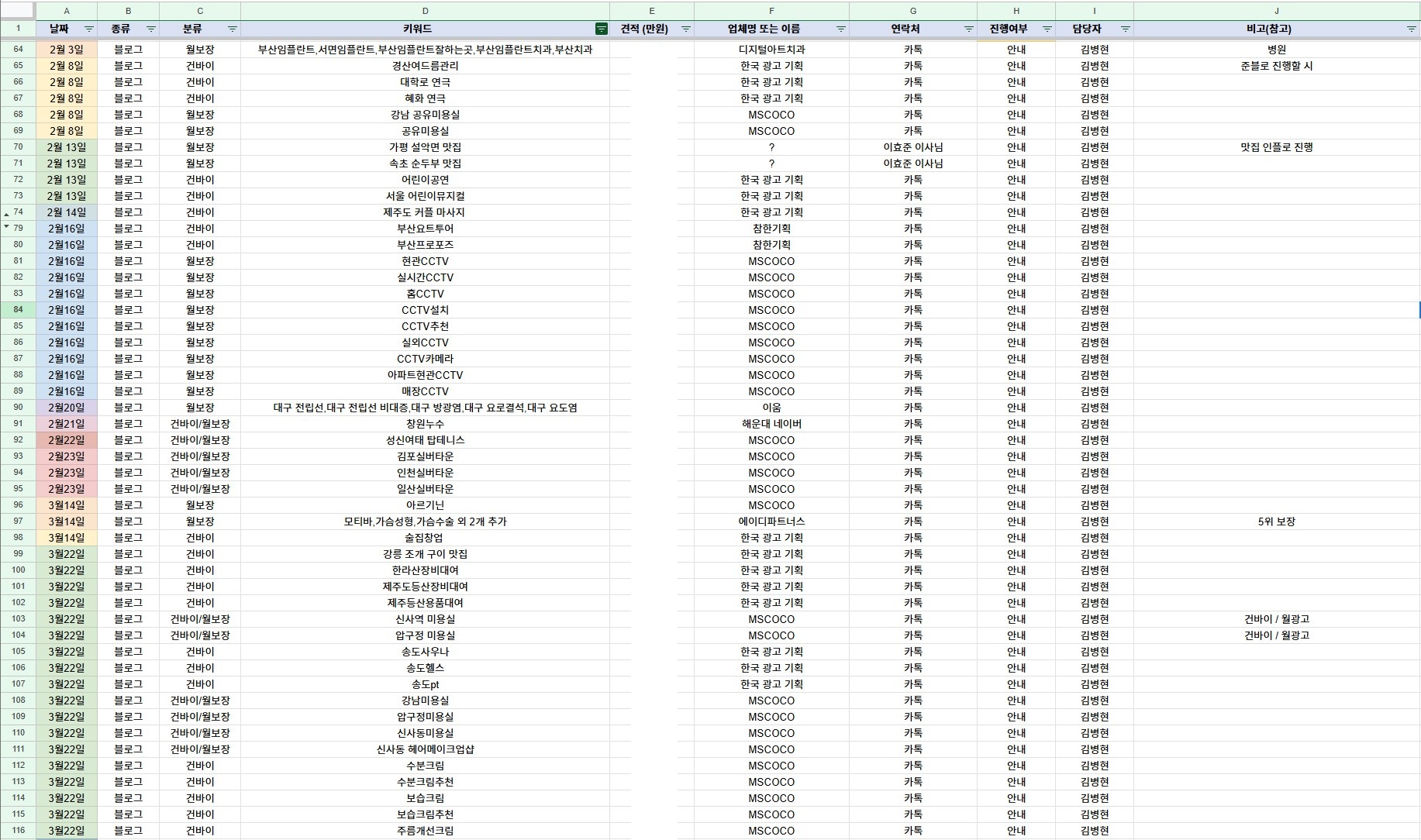
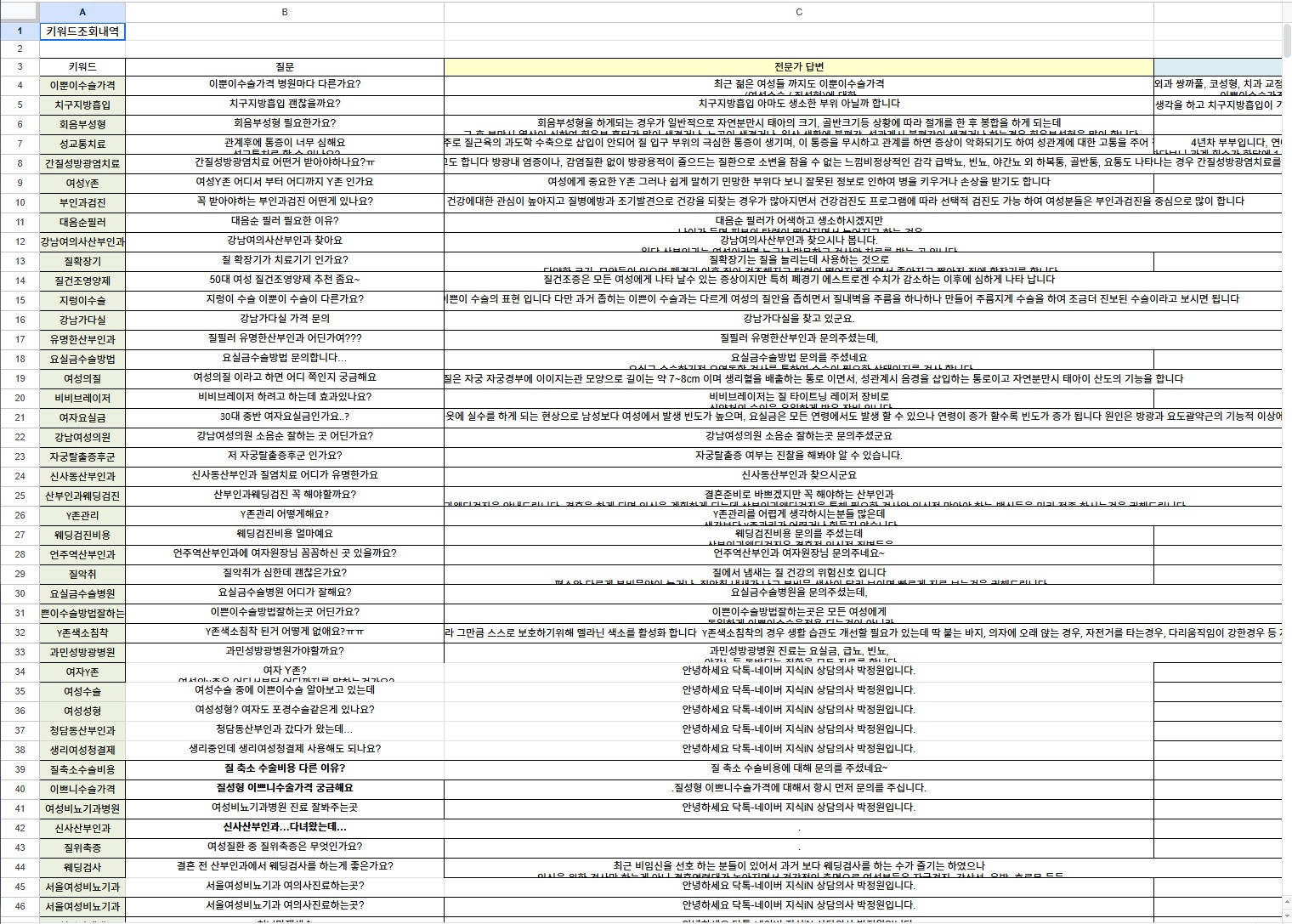
근무한 기간 동안 29개의 병원 업체를 관리하였습니다.
1-2. 파이썬을 이용한 문서 비교 프로그램
진행 배경
-
코로나19로 회사 매출이 급감하던 시기,
새로운 플랫폼에서 마케팅을 진행하기 위해 방대한 문서를 비교 분석해야 했습니다.
그러나 시중 프로그램의 높은 사용료로 인해 활용을 절제할 수밖에 없었습니다.
이에 저는 파이썬을 독학하며 챗GPT의 도움을 받아
문서 비교 분석 프로그램을 직접 개발했습니다.
그 결과, 분석 시간을 하루에서 5분으로 단축하고,
비용 부담 없이 효율적으로 전략을 수립할 수 있었습니다.
기능 설명
| 기능 | 설명 |
|---|---|
| 대규모 문서 분석 | 키워드 빈도와 총 문자 수를 자동 집계하여 방대한 데이터를 신속히 처리 |
| 중복 단어 탐지 | 여러 파일에서 중복 단어를 비교 분석해 핵심 메시지 도출 |
| 단어 삽입 자동화 | 특정 단어를 균형 있게 삽입해 SEO 전략에 활용 |
def count_words_in_files(directory, words):
files = [f for f in os.listdir(directory) if f.endswith('.txt') or f.endswith('.docx')]
word_frequencies = pd.DataFrame(index=words)
for file in files:
if file.endswith('.txt'):
with open(os.path.join(directory, file), 'r', encoding='utf-8') as f:
contents = f.read().lower()
elif file.endswith('.docx'):
contents = read_docx(os.path.join(directory, file)).lower()
file_word_frequencies = {word: count_keyword_in_text(contents, word) for word in words}
word_frequencies[file] = pd.Series(file_word_frequencies)
return word_frequencies2. 양주시 클라우드 캠프 (24.04 ~ 23.10)
2-1. AWS를 이용한 스트리밍 서비스 프로젝트
진행 배경
- 양주시 클라우드 캠프에서 배운 AWS 지식을 응용해
팀 프로젝트로 스트리밍 서비스를 구축했습니다.
이 과정에서 AWS 인프라를 깊이 이해하게 되었고,
팀원들과의 긴밀한 협업을 통해 문제 해결 능력과
협업 스킬을 한층 더 발전시킬 수 있었습니다.
이를 통해 실질적인 성과를 도출하며 팀워크의 중요성을 체감한 경험입니다.
진행 과정

1단계
아이디어 회의

2단계
아키텍쳐 구상

3단계
맡은 업무 수행

4단계
결과물 제작
맡은 업무
| 기능 | 설명 |
|---|---|
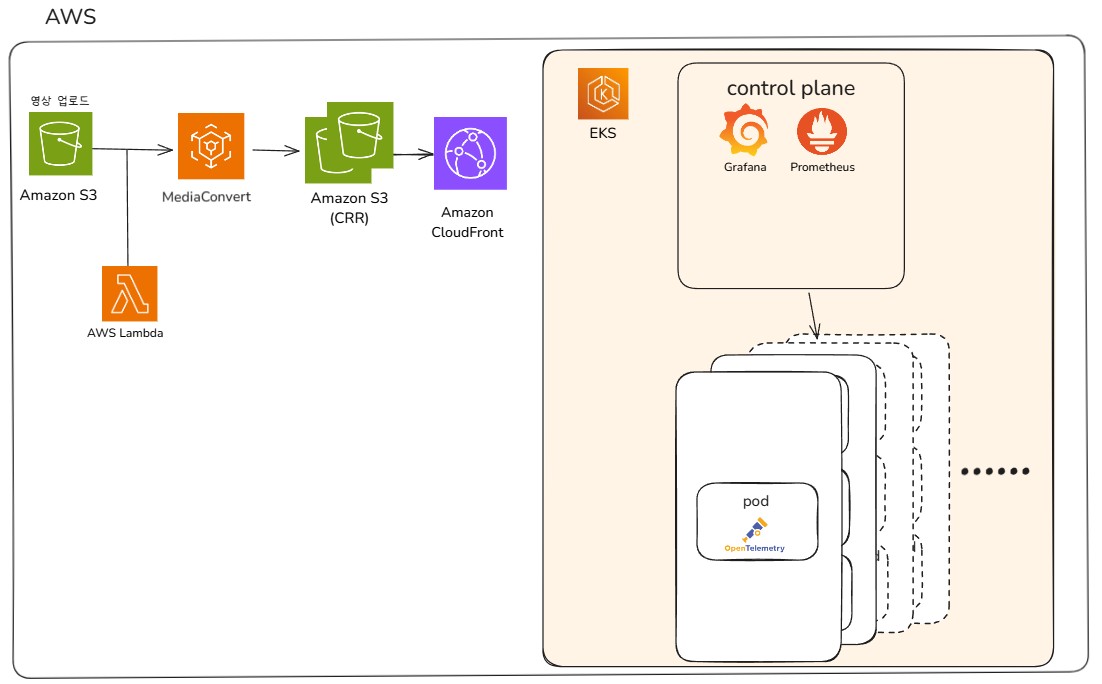
| 미디어 처리 및 배포 자동화 솔루션 | AWS Lambda와 MediaConvert를 활용해 S3와 CloudFront 기반의 효율적인 미디어 처리 및 배포 시스템을 구축했습니다. |
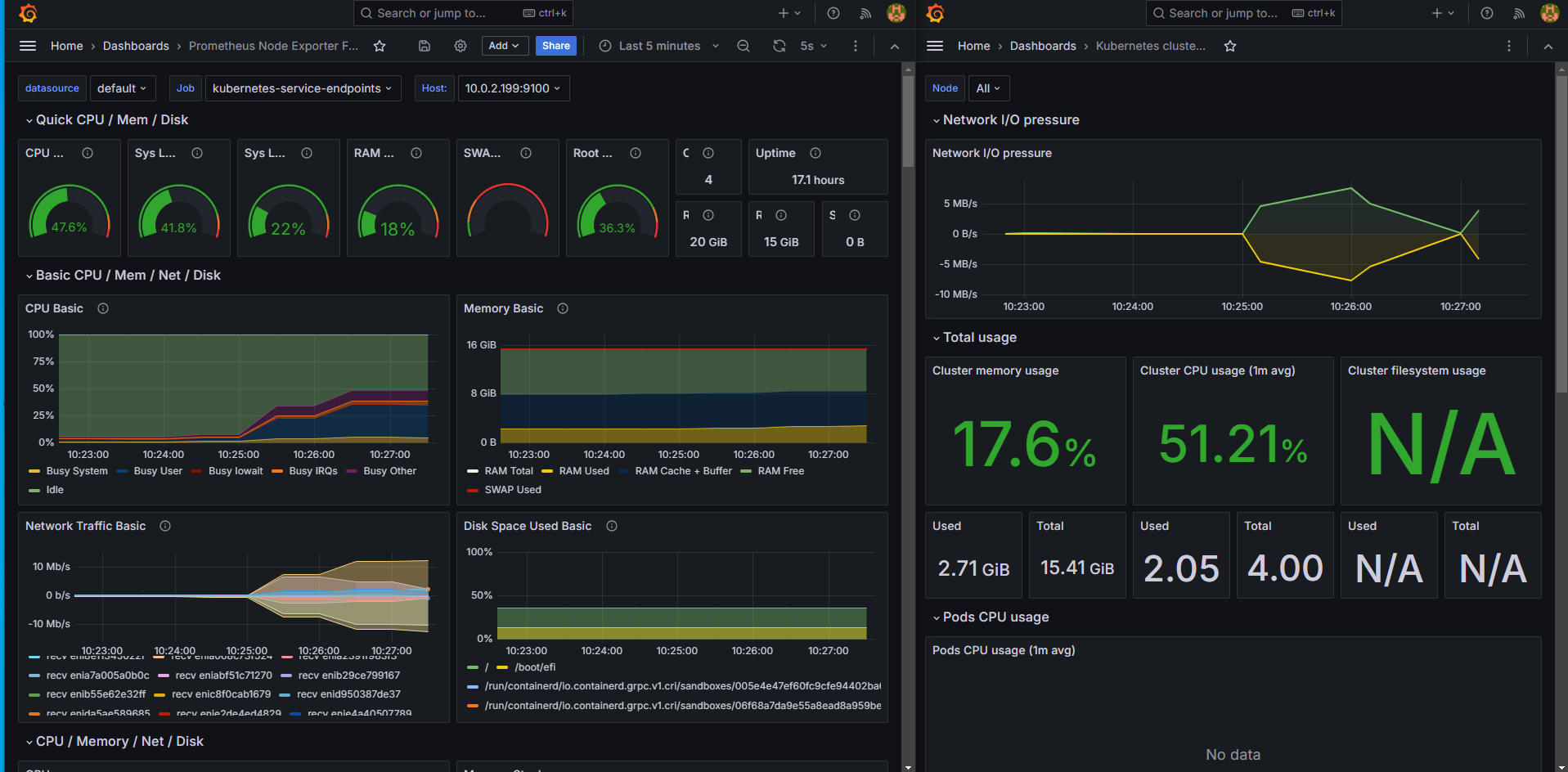
| 실시간 로그 모니터링 대시보드 | Prometheus와 Grafana로 로그를 시각화하여 실시간 모니터링이 가능한 클라우드 기반 대시보드를 구현했습니다. |

AWS Lambda
지정된 작업을 자동으로 처리해주는 서버리스 서비스입니다.

AWS S3
중요한 데이터를 안전하게 저장하고 쉽게 접근할 수 있는 클라우드 저장소입니다.

AWS CloudFront
전 세계 어디서나 빠르게 콘텐츠를 전달할 수 있는 CDN 서비스입니다.

AWS MediaConvert
비디오 파일을 다양한 기기와 플랫폼에서 사용할 수 있도록 변환해주는 서비스입니다.
수행 이미지
시연 영상

3. 토이 프로젝트
3-1. 크롤링 - 데이터 수집
진행 배경
- 효율적인 데이터 수집의 중요성을 깨닫고,
크롤링 기술을 학습하는 토이 프로젝트를 진행했습니다.
이를 통해 마케팅 데이터를 자동화하여 수집하고 분석할 수 있는 가능성을 탐구했으며,
데이터 기반 마케팅 전략에 필요한 기술적 이해를 확장하는 계기가 되었습니다.
이러한 학습은 타겟 고객 분석 및 시장 동향 파악에
활용할 수 있는 역량을 키우는 데 초점을 맞췄습니다.
진행 과정
1단계
키워드 입력
2단계
제품 목록 수집 및 저장
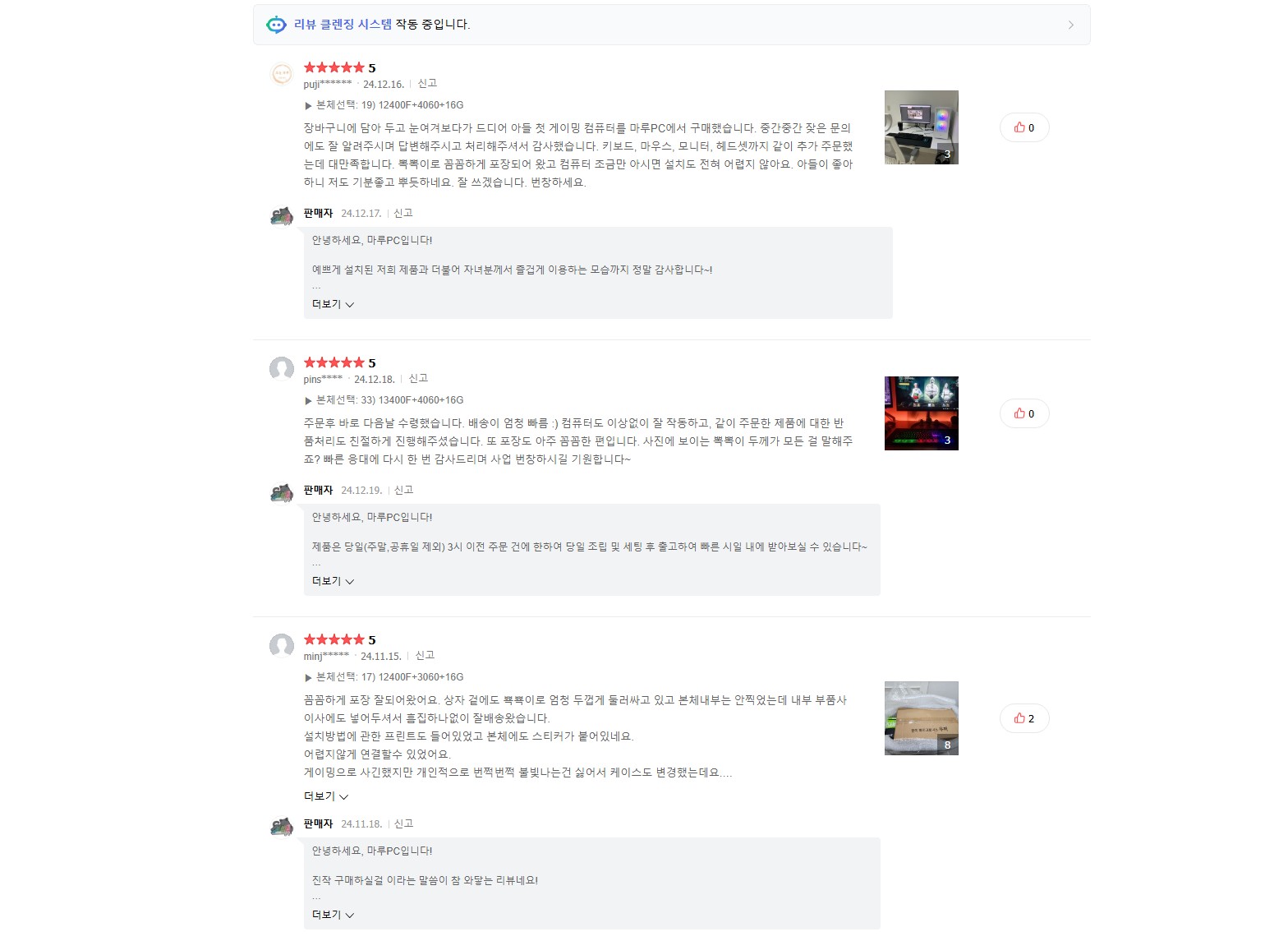
3단계
리뷰 추출 및 저장
4단계
다음 키워드 반복
수행 이미지
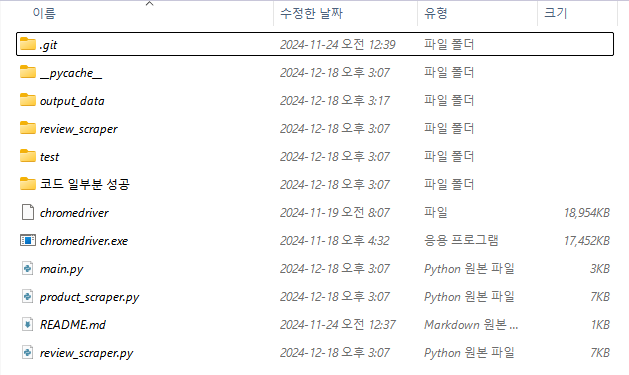
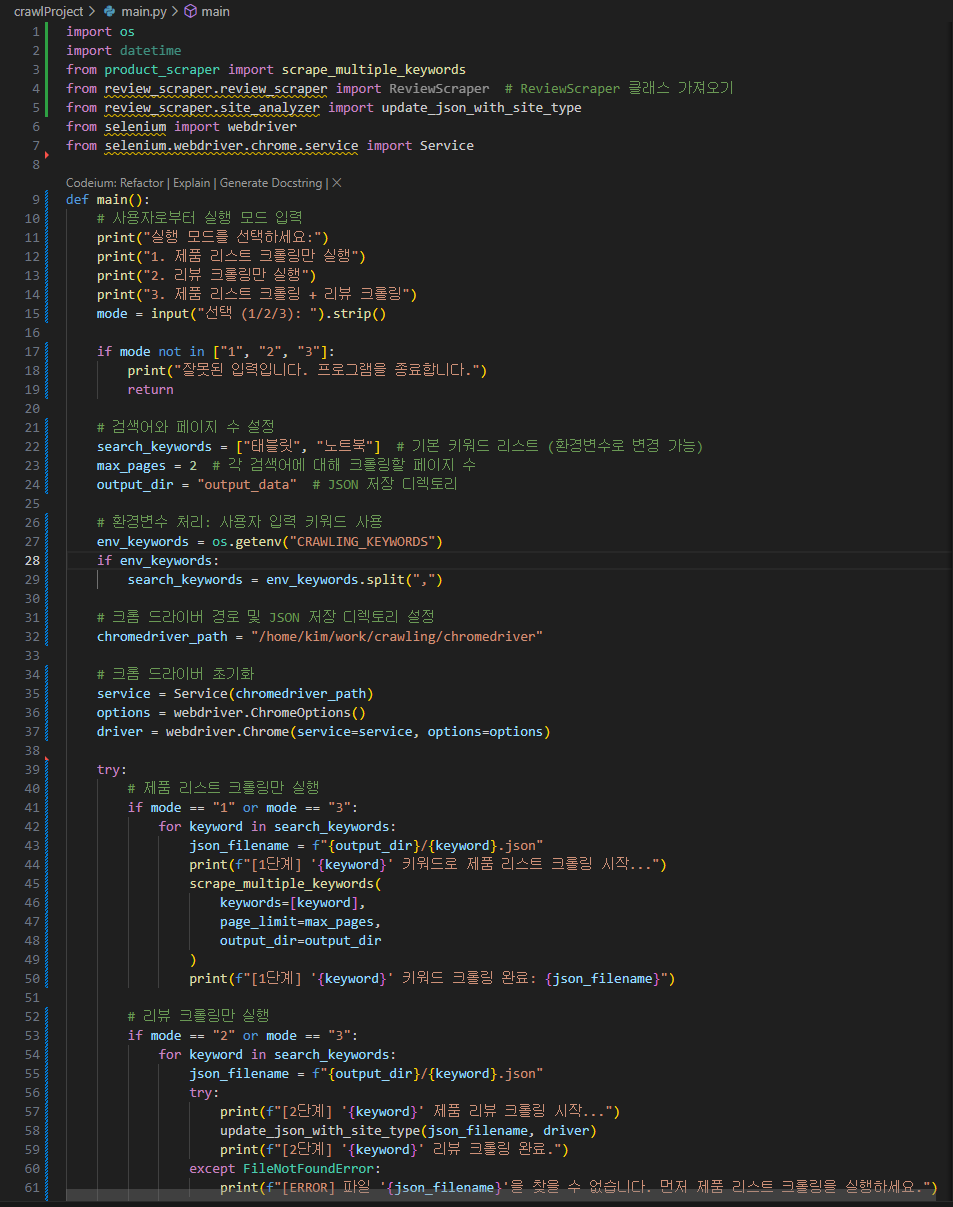
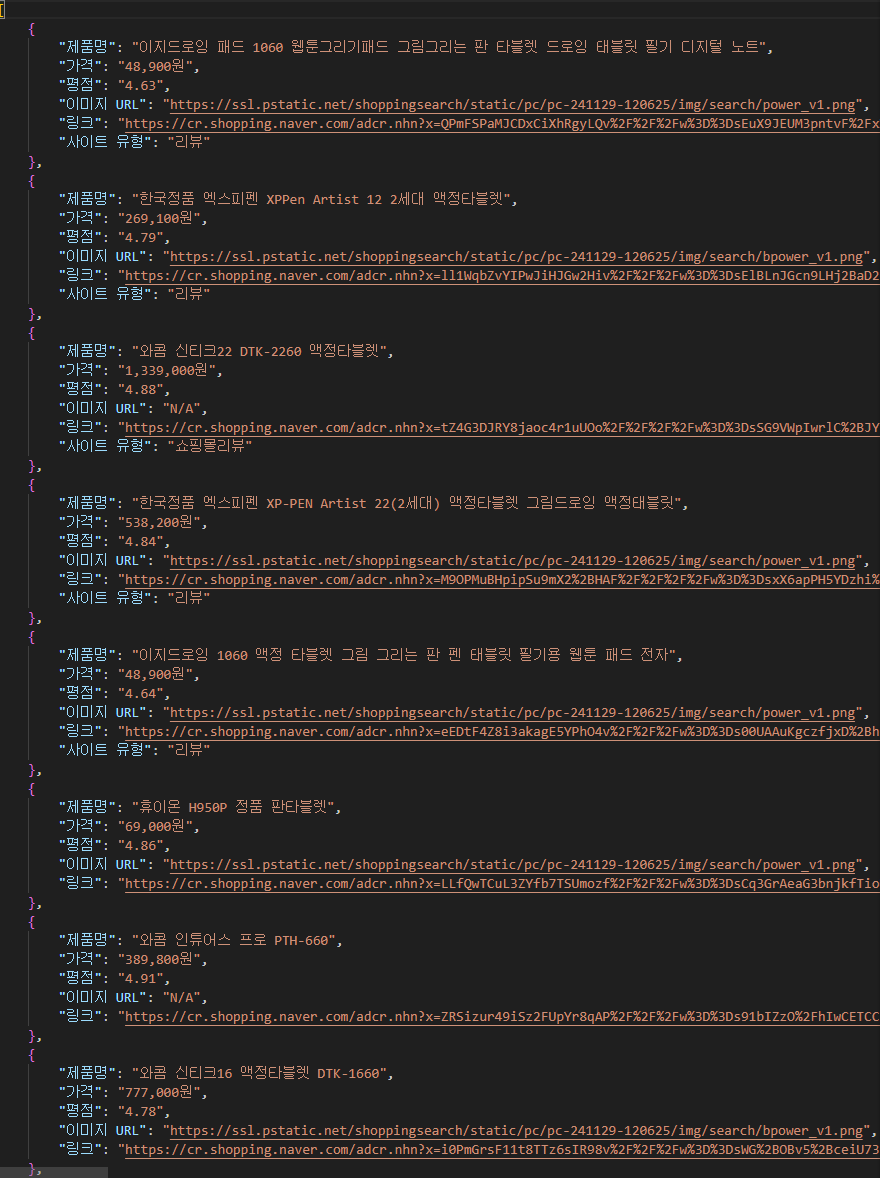
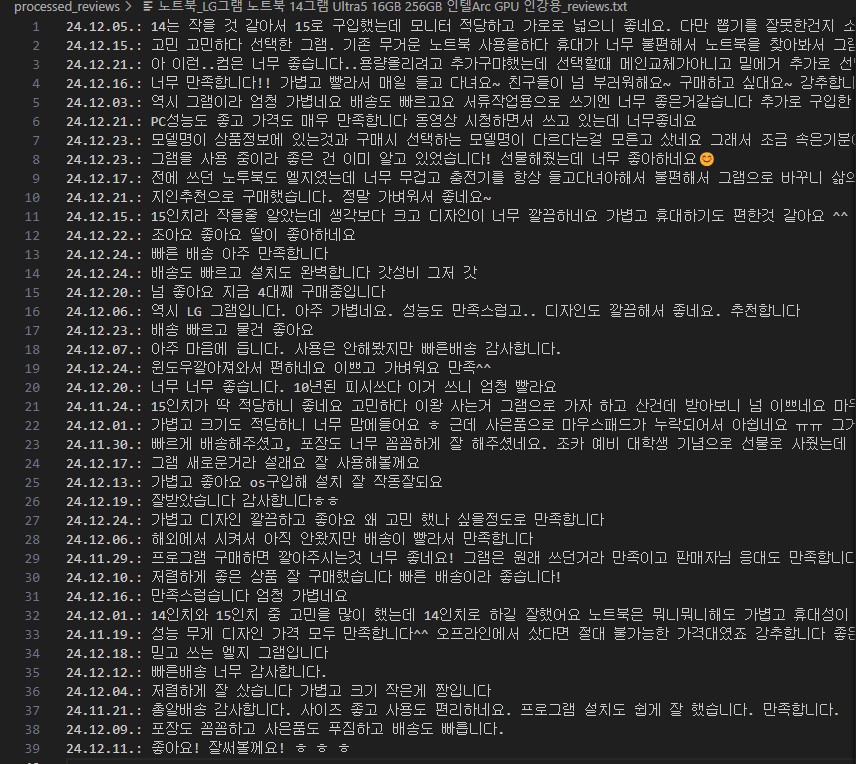
시연 영상

개발 예정
-
사용자들이 더욱 쉽고 편리하게 리뷰를
크롤링할 수 있도록 웹 기반 UI를 도입할 예정입니다.
수집된 리뷰 데이터는 자동으로 가공되어
엑셀 형식의 보고서로 생성됩니다.
-
이 보고서를 기반으로 사용자는 SWOT 분석과
소비자 트렌드 분석을 효율적으로 수행할 수 있으며,
이를 통해 분석에 소요되는 시간을 단축할 수 있습니다.
| 기능 | 설명 |
|---|---|
| 리뷰 요약 | 제품별 리뷰를 분석해 장점과 단점을 한 줄 요약으로 정리합니다. |
| 핵심 정보 제공 | 각 제품의 평점과 가격 정보를 포함합니다. |
Thank you
방문해 주셔서 감사합니다.
앞으로도 데이터 공부와 창의력을 결합해 더 나은 가치를 만들어 가겠습니다.